
npm, yarn, pnpm 相关机制和原理的介绍
前端包管理机制简述
从package.json文件说起
package.json是前端领域中用来描述一个包信息的描述文件. 其中, 只有两个字段是必填的:
name: 模块名称, 可以用validate-npm-package-name来检测包名是否合法, 因为包名是唯一的, npm也提供npm view packageName来检测包名是否被占用.version: 模块版本, npm的模块版本遵循SemVer规范, 即主版本号.此版本号.修订号. 可以使用semver包来进行比较版本, 提取版本信息等操作.
依赖管理
在package.json中, 另外比较重要的配置就是依赖的管理了.
依赖配置相关的字段主要有下面这些:
dependencies: 指定了项目运行所依赖的模块devDependencies: 一些只用于开发时的包, 可以用该字段进行管理, 在运行时不会用到的依赖,比如Eslint等等. 将这些依赖保存在次数,可以避免在生产环境被安装.peerDependencies: 用于指定你正在开发的模块所依赖的模块的版本, 以及用户安装的依赖包版本的兼容性. 在npm3以后就不会强制安装peerDependencies中依赖的版本, 而是抛出一个warn. 不影响继续安装其他的依赖bundledDependencies: 提供一个包名的数组, 会在发布的时候被一起打包optionalDependencies: 如果你的依赖是可有可无的,并且又在安装的时候无法获取到,那么就可以把依赖放在这里,npm在安装的时候就不会报错了.
依赖中的每一项都会按照版本控制的规则进行控制, 我们常见的版本控制的写法有这么几种:
"xxx": "1.0.0": 固定版本号"xxx": "*": 任意的版本号"xxx": "16.x": 表示匹配主要的版本号(这里即16.0.0<= version <17.0.0)"xxx": "16.3.x": 表示匹配主要版本和次要版本(这里即16.3.0 <= version <16.4.0)"xxx": "~1.0.0": 保持主版本号和次要版本号不变的情况下, 安装小版本中的最新版本"xxx": "^1.0.0": 保持主版本号不变的情况下, 安装次要版本号和修订版本号为最新的版本
这里^是npm install的时候采用的默认的安装版本方式.
另外, 当主版本号是0的时候就会被认为是一个不稳定版本, 版本控制的逻辑有所不同.
- 如果主要版本和次要版本都是0, 那么
~0.0.z和^0.0.z都会直接被当做固定版本. - 如果主要版本为0, 那么
^0.y.z和~0.y.z相同, 只保持z为最新的版本
依赖锁定
在一些场景下, 我们不希望依赖被更新, 所以会在package.json的同级目录下, 生成一个lock文件.
这个文件的作用是: 在不执行手动更新的情况下, 每次都安装固定的版本, 从而保证每次都使用一致的依赖.
在使用package-lock的情况下要确保npm的版本在5.6以后以获得比较稳定的版本控制.
升级依赖
使用npm outdated可以列出所有依赖的最新版本情况的表格, 包名会渲染到不同的颜色:
- 黄色: 不符合我们指定的版本范围, 不需要升级
- 红色: 符合我们指定的语义化版本范围, 需要升级
然后指定npm update就会自动升级所有的红色依赖.
npm的包管理机制
在早期的npm包管理中, npm会简单粗暴的, 把所有依赖以递归的方式, 严格按照package.json中的结构以及子依赖包的package.json结构安装到他们各自的node_module中. 直到子依赖包不再依赖其他的模块.
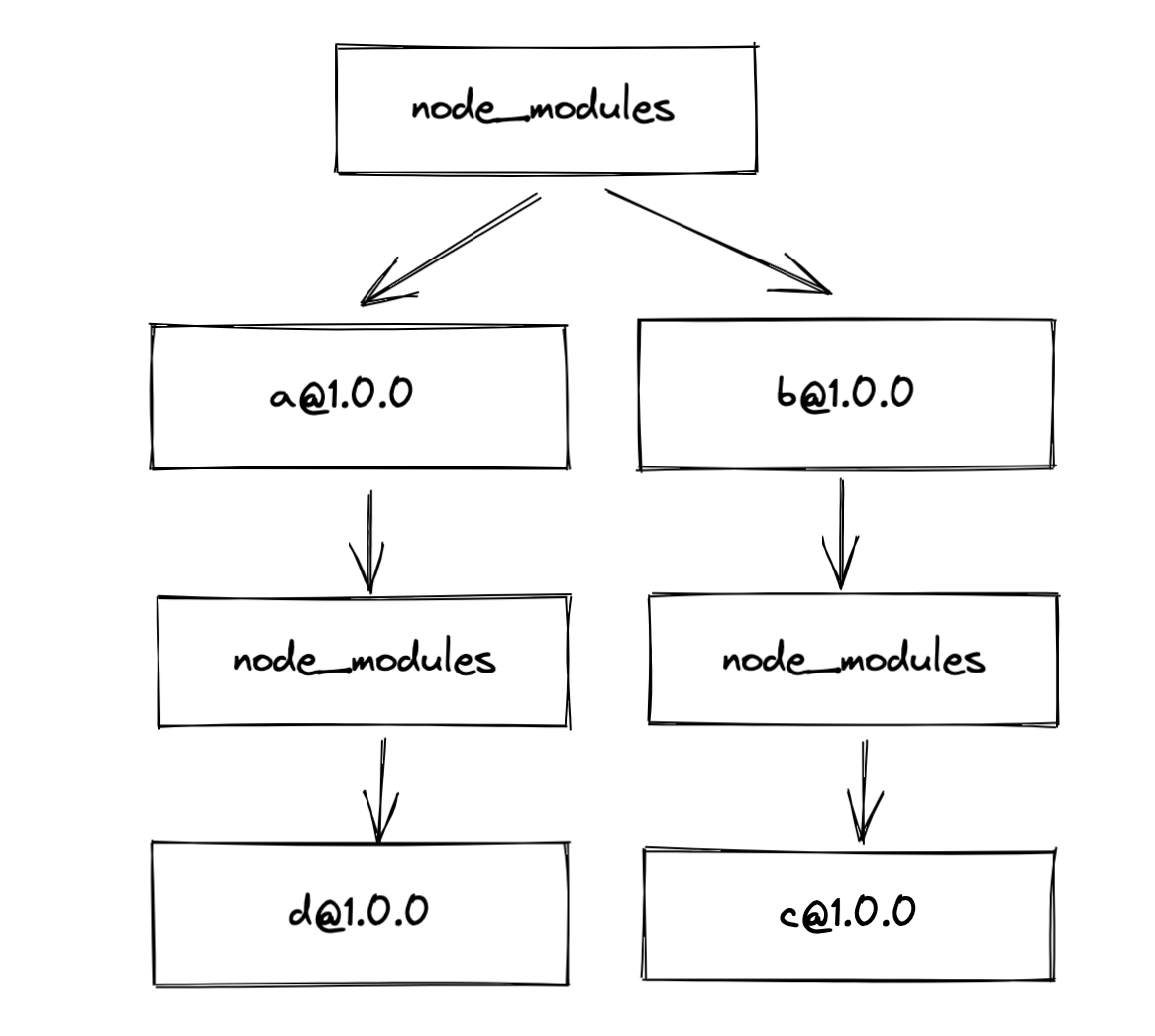
虽然这种管理方式, 对于依赖的层级看起来非常清晰, 但是也会存在依赖冗余的问题. 比如两个子依赖都依赖同一个项目, 那么这个项目会被安装两次, 并且整个项目的嵌套层级非常深.
为了解决这个问题, npm在3.x对嵌套结构进行了打平, 也就是说, 安装模块的时候, 会把直接依赖和子依赖以及子依赖的依赖都优先安装在node_modules的根目录下面.
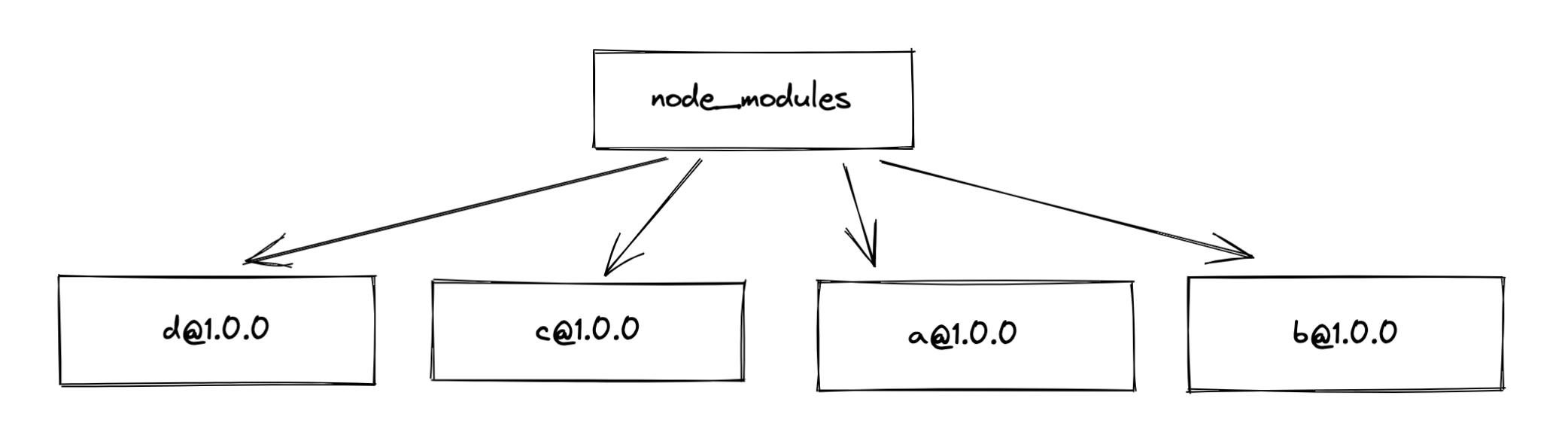
假如, A依赖包和B依赖包都依赖项目C, 并且依赖了不同的版本, 那么在安装到这个模块的时候:
- npm会判断已经安装的模块是否符合版本范围, 符合则跳过
- 不符合则在当前模块的
node_modules下安装该模块.
此时, 我们可能会得到这样的目录结构:
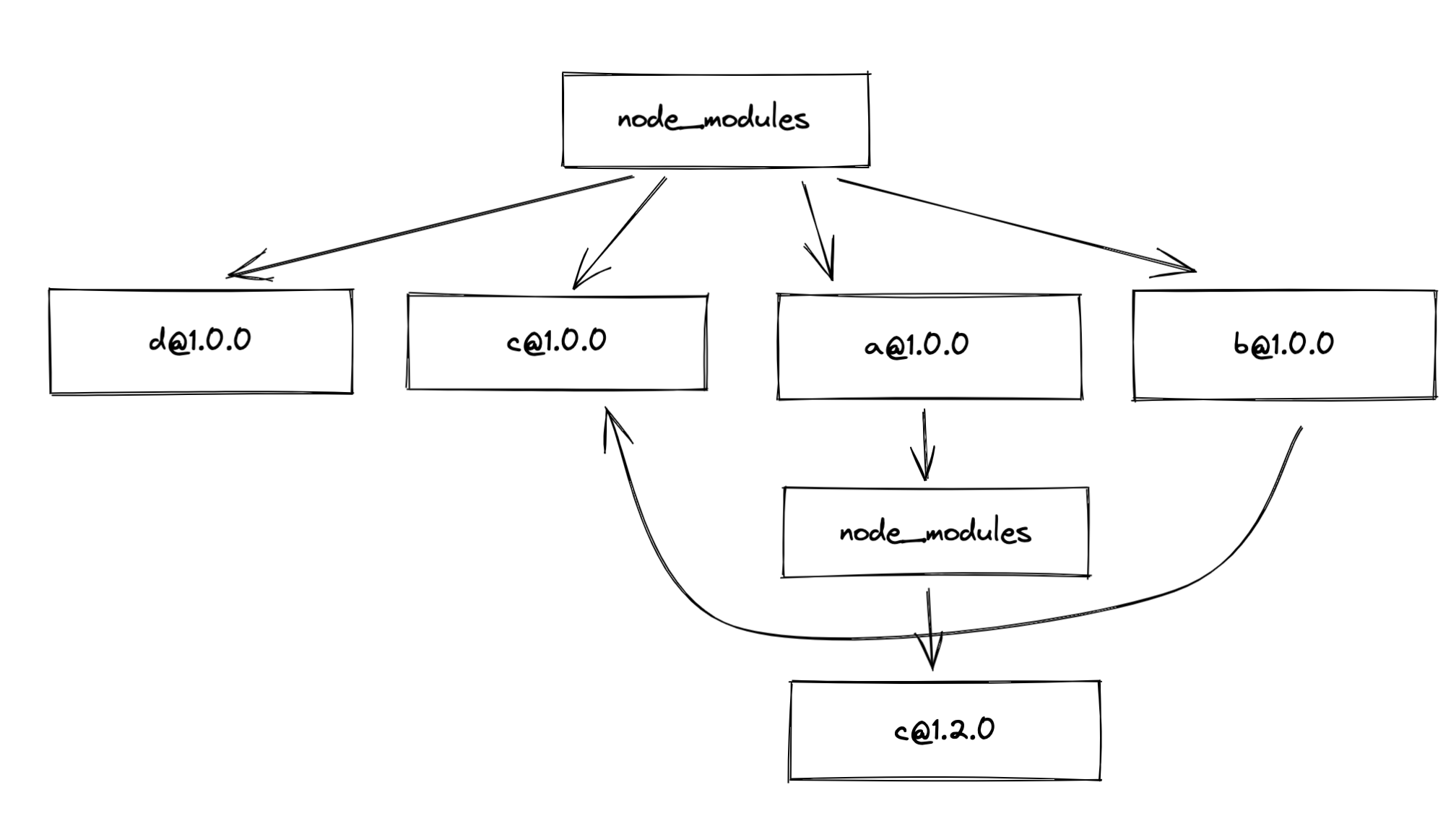
对应这样的目录结构, 当我们去搜索一个模块的时候, 对应的查找流程就是这样的:
- 在当前模块的路径下搜索
- 在当前模块的
node_modules路径下搜索 - 在上级模块的
node_modules路径下搜索 - ...
- 直到在全局路径中的
node_modules路径下搜索
在这种模式下, 我们解决了部分的模块依赖问题, 但是也带来了新的问题.
在npm install的时候, 是按照package.json中的模块顺序来依次的解析模块和安装依赖的, 也就是说, 模块的排列顺序就决定了最终生成的node_modules的目录结构.
比如, 当你的A依赖包和B依赖包都依赖C的不同版本, 那么node_modules中, 首层的C依赖的版本, 就取决于A和B在package.json中的先后顺序.
如果是先B后A:
如果是先A后B:
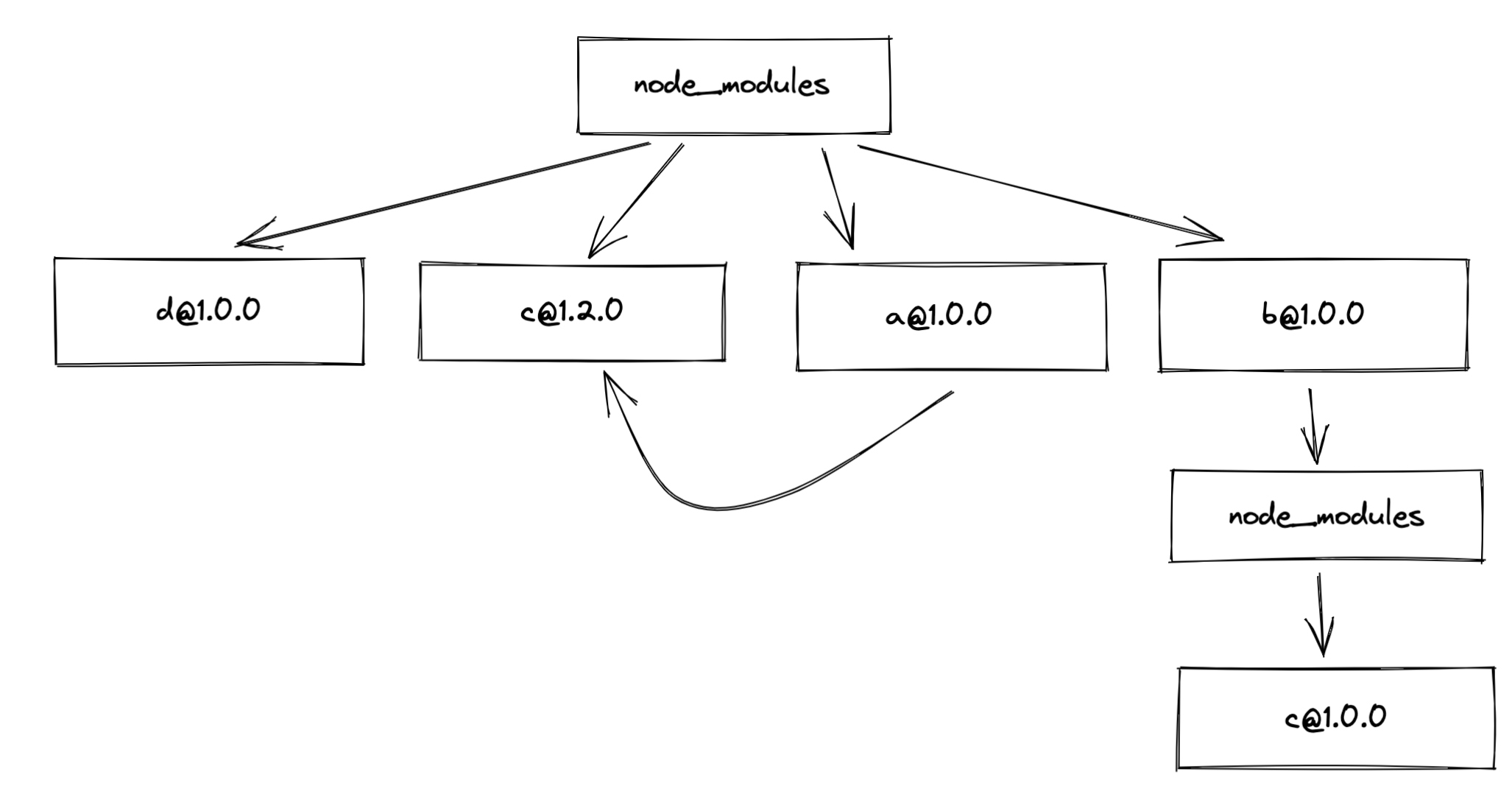
此外, 如果我们只在package.json中锁定大版本, 那么某些依赖包的小版本更新后, 同样会造成依赖结构的变化.
这种情况下, 我们就必须借助package-lock.json文件, 把所有的依赖版本确定下来, 这样才能固定node_modules的层级结构.
package-lock.json文件结构
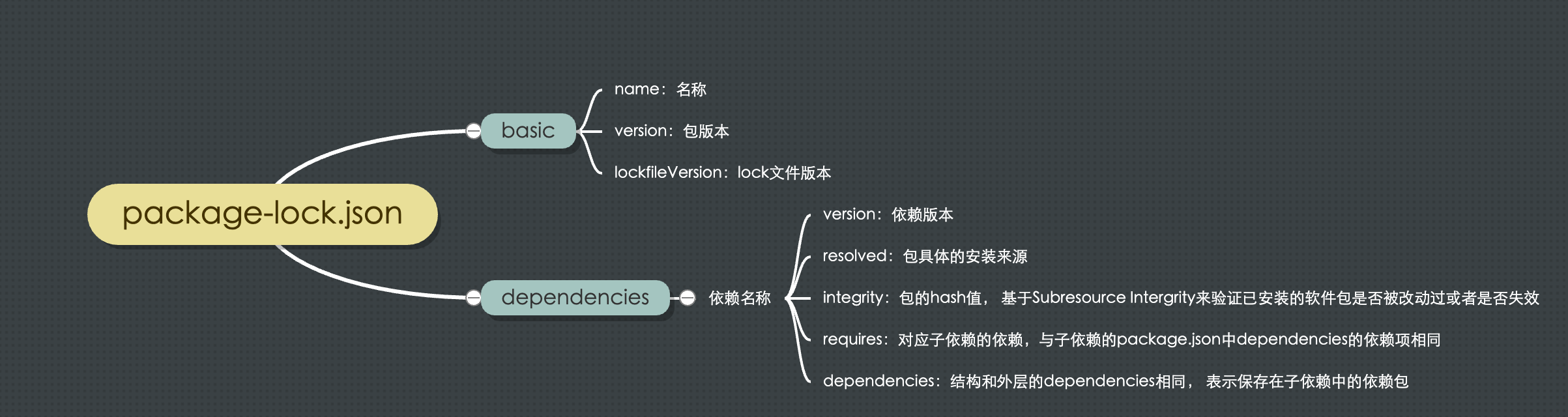
注意, 这里并不是所有子依赖都会有dependencies属性的, 只有子依赖和当前已经安装的依赖发生冲突之后, 才会有这个属性.
这样依赖, lock文件中的层级结构和实际的node_modules文件就是一一对应的, 以保证每次npm install生成的node_modules一样的层级结构.
lock还有一个好处, 因为已经缓存了每个包的具体的版本和下载的链接, 所以就不需要再去远程仓库进行查询, 直接在安装完成后, 进入文件完整性校验即可.
npm本地缓存
在使用npm install安装完依赖后, npm会在本地的缓存目录缓存一遍这些包.
我们可以通过npm config get cache查询到缓存所在的目录.
一般会在用户目录下.npm/_cacache目录下面, 这个目录下面存在两个目录:
content-v2: 存储tar包的缓存index-v5: 存储tar包的hash
npm在执行安装的时候, 会根据lock文件中的intergrity, version, name生成一个唯一的key对应到index-v5目录下面的缓存记录, 从而找到tar包的hash, 然后根据hash去缓存中找到对应的tar包直接使用.
在
npm v5之前, 是直接通过{cache}/{name}/{version}这样的结构表示的.
常用的用于缓存的npm命令有:
npm cache clean: 清除缓存, 为了保证缓存数据的完整性, 一般会加上--force参数npm cache verify: 验证缓存数据的有效性和完整性, 清理垃圾数据
基于缓存, npm提供了离线安装模式:
--perfer-offline: 优先使用缓存, 如果没有则从远程仓库下载--perfer-online: 优先使用网络数据, 如果网络请求失败, 再使用缓存数据--offline: 不请求网络, 直接使用缓存数据, 一旦缓存不存在, 就安装失败
yarn的包管理机制(yarn1)
yarn出现在2016年, 当时npm还处于v3版本, 也就是简单粗暴的递归模式. 没有扁平化依赖, 没有lock文件. yarn针对原来npm的缺陷提出了自己的解决办法, 并对npm后续的更新造成了深刻的影响.
yarn的特性大致有这么一些:
- 生成
yarn.lock: 明确依赖版本和依赖结构, 在任何环境下都能得到一致的依赖结构 - 扁平化安装: 将依赖包的不同版本, 按照一定策略归化为一定的版本范围
- 使用并发请求: 类似并发连接池
- 引入了包缓存机制.
我们这里讨论的是yarn1的版本管理模式.
yarn.lock版本锁定
与npm的package-lock.json不同, yarn.lock使用的是一种自定义的文件格式.
除此之外, yarn.lock中子依赖的版本号是不固定的, 这就意味着单独的yarn.lock是没有办法确定node_modules的目录结构的, 还需要和package.json文件组合. 而package-lock.json则只需要它自己就可以了.
yarn.lock的文件内容看起来像这样:
# THIS IS AN AUTOGENERATED FILE. DO NOT EDIT THIS FILE DIRECTLY.
# yarn lockfile v1
"@tootallnate/once@1":
version "1.1.2"
resolved "https://registry.yarnpkg.com/@tootallnate/once/-/once-1.1.2.tgz#ccb91445360179a04e7fe6aff78c00ffc1eeaf82"
integrity sha512-RbzJvlNzmRq5c3O09UipeuXno4tA1FE6ikOjxZK0tuxVv3412l64l5t1W5pj4+rJq9vpkm/kwiR07aZXnsKPxw==
address@>=0.0.1, address@^1.0.0:
version "1.1.2"
resolved "https://registry.yarnpkg.com/address/-/address-1.1.2.tgz#bf1116c9c758c51b7a933d296b72c221ed9428b6"
integrity sha512-aT6camzM4xEA54YVJYSqxz1kv4IHnQZRtThJJHhUMRExaU5spC7jX5ugSwTaTgJliIgs4VhZOk7htClvQ/LmRA==
你可以发现, 在yarn.lock文件中, 每个包的版本是一个逗号拼接的数组, 他表示所有的依赖该包的范围. 每个包下面都有对应的字段, 这些字段的含义和package-lock.json中的定义是类似的:
- version: 符合包的语义化版本的确切的一个版本
- resolved: 记录包的地址, 此外, hash中的值是
shasum - dependencies: 记录当前包的依赖
yarn会把所有包的依赖提升到顶层去. 对于可以合并的同名依赖, 就用逗号分隔, 作为顶层的一个key, 对于不能合并的, 则视为两个独立的顶层Key.
在具体的node_modules文件中, 则只会出现最新版本的包.
比如说, 我们现在的项目中依赖同一个包的两个版本:
fs-extra@^8.1.0:
version "8.1.0"
resolved "https://registry.yarnpkg.com/fs-extra/-/fs-extra-8.1.0.tgz#49d43c45a88cd9677668cb7be1b46efdb8d2e1c0"
integrity sha512-yhlQgA6mnOJUKOsRUFsgJdQCvkKhcz8tlZG5HBQfReYZy46OwLcY+Zia0mtdHsOo9y/hP+CxMN0TU9QxoOtG4g==
dependencies:
graceful-fs "^4.2.0"
jsonfile "^4.0.0"
universalify "^0.1.0"
fs-extra@^9.0.1:
version "9.1.0"
resolved "https://registry.yarnpkg.com/fs-extra/-/fs-extra-9.1.0.tgz#5954460c764a8da2094ba3554bf839e6b9a7c86d"
integrity sha512-hcg3ZmepS30/7BSFqRvoo3DOMQu7IjqxO5nCDt+zM9XWjb33Wg7ziNT+Qvqbuc3+gWpzO02JubVyk2G4Zvo1OQ==
dependencies:
at-least-node "^1.0.0"
graceful-fs "^4.2.0"
jsonfile "^6.0.1"
universalify "^2.0.0"
这两个版本不可合并, 所以yarn会把它们两个都放在yarn.lock文件中.
但是在node_modules文件夹下, 默认会放置fs-extra@9.0.1版本的模块, 而fs-extra@8.1.0这个包会放在对应引用它的依赖的node_modules文件夹中.
这里和npm的处理逻辑有所不同.
yarn缓存管理
类似于npm的cache命令, yarn也提供了几个缓存管理命令:
yarn cache ls: 列出当前缓存的包的列表yarn cache dir: 显示缓存的目录yarn cache clean: 清理缓存
一般, yarn的缓存目录默认放在Library/Caches/Yarn/的目录下面, 具体的你可以通过命令调用查看.
Yarn的缓存管理要显得更加语义化一些:
- npm-yorkie-2.0.0-92411912d435214e12c51c2ae1093e54b6bb83d9-integrity
- npm-zeromq-5.2.8-94b0b85e4152e98b8bb163f1db4a34280d44d9d0-integrity
- npm-zrender-5.1.1-0515f4f8cc0f4742f02a6b8819550a6d13d64c5c-integrity
- npm-zscroller-0.4.8-69eed68690808eedf81f9714014356b36cdd20f4-integrity
- npm-zwitch-1.0.5-d11d7381ffed16b742f6af7b3f223d5cd9fe9920-integrity
它的缓存目录下面都是类似这样的文件夹, 文件的的名称以npm-开头, 以包名, 版本号以及hash值组成.
yarn默认使用的是perfer-online模式, 也就是说, 它会先尝试从远程仓库下载, 如果连接失败则在尝试从缓存中读取. 如果你希望采用离线优先策略, 也提供了--offline参数:
yarn add --offline
此外, yarn是支持配置离线镜像的:
yarn config set yarn-offline-mirror ./npm-packages-offline-cache
离线镜像不同于缓存. 缓存是从注册中心下载的解压缩的tar包, 这些缓存是基于特性的工具实现的, npm有npm的缓存, yarn有yarn的缓存, 并且还有可能在npm的不同版本下机制也是不同的. 而离线镜像中的tar包不会受到工具和工具版本的影响, 并且存储后的文件也有利于存储. 更详细的步骤可以参照官方文档
(实际上, 我们看到在npm的缓存机制下, 缓存包是以tar形式保存的)
pnpm的包管理机制
npm的v3以后的版本管理和yarn1的版本管理都采用了将依赖打平的方式, 这么做的好处在于减少层级深度和依赖冗余, 但是也带来的新的问题:
- 最严重的问题就是幽灵依赖的问题, 模块可以访问它们不依赖的包
- 压平依赖的树算法非常的复杂
- 一些包必须复制到一个项目的
node_modules文件中
我们回顾之所以要将包进行扁平化的理由:
- 在原来的npm的包管理机制下,
node_modules会发生很深的嵌套. - 大量的相同依赖冗余在不同的依赖包中.
pnpm实际上是提出了另一种解决这个问题的方法, 即利用硬链接将所有的包集中到全局管理.
也就是说, node_module文件夹中还是保持了和依赖图谱完全一致的文件目录结构, 但是又能避免依赖冗余和层级过深的问题.
在linux中, 硬链接就是指通过索引节点来进行链接. 在linux的文件系统中, 保存在磁盘分区中的文件不论是什么类型都会给它分配一个编号, 称为索引节点号. 在Linux中, 多个文件名指向同一个索引节点号是被允许的. 也就是说, linux允许文件拥有多个有效路径.
基于这种机制, pnpm把所有的依赖包都防止在.pnpm文件下面, 在.pnpm中平铺的存储这所有的包, 所以每个包都可以在以这种命名模式的文件夹中被找到:
.pnpm/<name>@<version>/node_modules/<name>
官方称之为: 虚拟存储目录.
这样的存储结构避免的npm-v3之前的版本中嵌套node_modules引起的长路径的问题, 也与npm-v3之后的版本中的平铺结构不同, 它保留了依赖包之间的真实的拓扑结构.
这么处理依赖, 带来了几个好处:
- 保留了严格对应的node_modules层级关系,
node_modules文件夹中只会存在真实依赖的依赖项 - 由于模块是全局共享的, 这解决了项目包的大小问题, 并且由于
pnpm采用缓存优先的策略, 使得包复用的概率变的很高, 项目依赖的二次安装速度大大提升. - 没有打平依赖带来幽灵依赖的问题
pnpm中的peerDep依赖问题
假设, 我们现在有两个项目package-a和package-b:
package-a依赖lib-a@1.0.0和lib-b@1.0.0package-b依赖lib-a@1.0.0和lib-b@1.1.0lib-a存在一个peerDeps是lib-b@^1.0.0
如果我们现在在项目中要同时安装package-a以及package-b, 在.pnpm中, 需要把所有依赖铺平:
package-a
package-b
lib-a@1.0.0
lib-b@1.0.0
lib-b@1.1.0
显然, package-a和package-b是分别依赖lib-b的两个版本的, 但是lib-b同时是lib-a的依赖, 那么导入lib-a的时候应该处理哪一个lib-b呢? 显然不能随便选择一个, 因为package-a和package-b都是依赖lib-a的, 随便挑一个另一个就会报错.
所以这种情况下, lib-a就会在pnpm中.pnpm里面出现两次, 一次链接到lib-b@1.0.0, 一次链接到lib-b@1.1.0.
也就是说, 我们得到了以下的.pnpm目录:
package-a
package-b
lib-a@1.0.0+lib-b@1.0.0
lib-a@1.0.0+lib-b@1.1.0
lib-b@1.0.0
lib-b@1.1.0
yarn2, PnP模式
PnP模式比起pnpm的全局硬链接模式更加激进一些, 它直接把node_modules给干掉了.
在PnP模式下, Yarn会维护一张静态的映射表, 这个表中会包含:
- 当前依赖树中包含了哪些依赖包以及对应的版本组
- 这些依赖包的依赖关系
- 这些依赖包在文件系统中的具体位置
这个映射表以.pnp.js文件的形式保存在项目的根目录下.
在项目进行依赖安装的时候, yarn不会把依赖拷贝到node_modules目录, 而是会在.pnp.js中记录下该依赖在缓存中的具体位置. 这样就避免了大量的I/O操作, 同时在项目中也不会生成node_modules目录.
PnP模式的优点在于:
- 完全摆脱了
node_modules的限制 - 提高了模块的加载效率: 通过
.pnp.js文件就能直接定位到具体的模块的地址, 省去了一层层查找模块位置的过程 - 不再受同名模块的不同版本不能在同一个目录的限制(npm中对这种情况就会创建出比较复杂的层级结构)
PnP模式的最大问题就是兼容性问题, 比如目前来说, 前端的很多工具都依赖于node_modules的模块查找机制, 例如:
- Node的require
- Webpack的模块查找
- TypeScript的类型声明文件
- Babel, ESLint的插件的定位机制
等等
Deno的包管理
Deno不是包管理工具, 可以理解为一个新的JS运行时框架, 目的是为了解决原来node_modules带来的种种问题.
Deno的依赖引入是直接引入资源的可访问路径, 不论是url或者本地路径, 不做任何的模块化的处理. 类似于这样:
import { serve } from "https://deno.land/std@0.54.0/http/server.ts";
const s = serve({ port: 8000 });
console.log("http://localhost:8000/");
for await (const req of s) {
req.respond({ body: "Hello World\n" });
}
每个包的路径中包含了引入源+包名+版本号+模块, 全都塞进了一个Url中.
但是这种引入方式在工程量增大的时候, 可预见的会变的非常的复杂和难以管理, 势必要引入一套依赖管理的机制.
官方推荐的做法是, 在项目本地建立一个dep.ts的文件, 然后通过dep.ts文件去引入各种本地或者远程的项目依赖.
比如像这样:
/**
* deps.ts
*
* This module re-exports the required methods from the dependant remote Ramda module.
*/
export {
add,
multiply,
} from "https://x.nest.land/ramda@0.27.0/source/index.js";
然后在项目中这样引用:
/**
* example.ts
*/
import { add, multiply } from "./deps.ts";
function totalCost(outbound: number, inbound: number, tax: number): number {
return multiply(add(outbound, inbound), tax);
}
console.log(totalCost(19, 31, 1.2));
console.log(totalCost(45, 27, 1.15));
/**
* Output
*
* 60
* 82.8
*/
也就是说, 移除了包管理工具的概念, 直接在代码层面上组织和管理模块依赖. 对于这种为了去中心化而设计的依赖管理模式, 则需要见仁见智了.