网络模型概述
OSI 参考模型(七层模型)

五层网络协议体系结构概述
- 应用层(application layer): 通过应用进程间的交互来完成特定网络应用. 应用层协议定义的是应用进程间的通行和交互的规则. 对于不同的网络应用需要不同的应用层协议. 在互联网中应用层协议很多, 比如DNS, HTTP, SMTP协议等
- 传输层(transport layer): 负责向两台主机进程之间的通信提供通用的数据传输服务. 应用进程利用该服务传送应用层报文. 通用性指的是并不针对某一个特定的网络应用, 而是多种应用可以使用同一个运输层服务
- 网络层(network layer): 在选择合适的网间路由和交换节点, 确保数据及时传输. 在发送数据时, 网络层把运输层产生的报文段或用户数据包分装成分组和包进行传送. 在TCP/IP体系结构中, 由于网络层使用IP协议, 因此分组也叫IP数据报, 简称数据报.
- 数据链路层(data link layer): 链路层, 用于两台主机之间的数据传输
- 物理层(physical layer): 实现相邻计算机节点之间比特流的透明传送, 尽可能屏蔽掉具体传输介质和物理设备的差异.
协议概览

物理层概述

数据链路层

网络层概述

网络层是OSI参考模型的第三层, 它位于传输层和链路层之间, 网络层的主要目的是实现两个端系统之间透明的数据传输.
网络层的作用非常简单, 即将分组从一台主机移动到另外一层主机. 为了实现这个功能, 网络层需要两种功能:
转发: 因为在互联网中有很多路由器的存在, 而路由器是构成互联网的根本, 其中最重要的一个功能就是分组转发, 当一个分组到达某路由器的一条输入链路时, 该路由器会将分组移动到适当的输出链路. 转发是数据平面中实现的唯一功能
网络中存在两种平面的选择:
- 数据平面(data plane): 负责转发网络流量, 如路由器交换机中的转发表
- 控制平面(control plane): 控制网络的行为, 比如网络路径的选择
路由选择: 当分组由发送方流向接收方的时候, 网络层必须选择这些分组的路径. 计算这些路径的算法被称为路由选择算法(routing alogorithm).
也就是说, 转发是指将分组从一个输入链路转移到适当输出的链路接口的路由器本地动作. 而路由选择是指确定分组从源到目的地锁定为的路径的算则.
每台路由都有一个关键的概念: 转发表(forwarding table). 路由器通过检查数据包标头中字段的值, 来定位转发表中的项来实现转发. 标头中的值对应着转发表中的值, 这个值指出了分组将被妆发的路由器输出链路.
传输层
应用层

常见问题
ARP协议简述
网络层的ARP协议完成了IP地址与物理地址的映射.
首先, 每台主机都会在自己的APP缓冲区中建立一个ARP列表, 以表示IP地址和MAC对应关系. 当源主机需要将一个数据包要发送到目的主机时, 会首先检查自己ARP列表中是否存在该IP地址对应的MAC地址, 如果有, 就直接将数据包发送到这个MAC地址; 如果没有, 就像本地网段发起一个ARP请求的广播包, 查询次目的主机对应的MAC地址
ARP请求包含源主机的IP地址, 硬件地址, 以及目的主机的IP地址. 网络中所有的主机收到这个ARP请求后:
- 检查数据包中的目的IP是否和自己的IP一致.
- 如果不相同, 忽略此数据包
- 如果相同, 该主机首先将发送端的MAC地址和IP地址添加到自己的ARP列表, 告诉对方自己是他需要查找的MAC地址
- 源主机收到这个ARP响应包后, 将得到的目的主机的IP地址和MAC地址添加到自己的ARP列表中, 并利用此信息开始数据的传输.
- 如果源主机一直没有收到ARP响应包, 表示ARP查询失败
路由器工作原理
路由器主要有4个组件构成:

- 输入端口(input port): 输入端口有很多的功能. 线路终端功能, 数据链处理功能. 这两个功能实现了路由器的单个输入链路相关联的物理层和数据链路层. 输入端口查找/转发功能: 对路由器的交换功能至关重要, 有路由器的交换结构来确定输出端口, 具体来将应该是查询转发表来确定的.
- 交换结构(switching fabric)就是讲路由器的输入端口连接到它的输出端口. 这种交换结构相当于是路由器内部的网络
- 输入端口(output ports): 通过交换结构转发分组, 并通过物理层和数据链路层的功能传输分组. 因此, 输出端口作为输入端口执行反向数据链接和物理层功能.
- 路由选择处理器(Routing processor): 在路由器内执行路由协议, 维护路由表并执行网络管理功能.
负载均衡有哪些实现方式?
- DNS: 最简单的负载均衡方式, 一般用于实现地理级别的负载均衡, 不同地域的用户通过DNS的解析可以返回不同的IP地址. 实现简单, 但是扩展性比较差, 控制权在域名服务商
- HTTP重定向: 通过修改Http响应头的Location达到负载均衡的目的, Http的302重定向. 这种方式影响性能
- 反向代理: 作用域应用层的模型, 也被称为七层负载均衡, 比如常见的Nginx, 性能一般可以达到万级. 这种方式部署简单, 成本低, 而且容易扩展.
- IP: 用作于网络层和传输层的模式, 也被称为四层负载均衡, 通过对数据包的IP地址和端口进行修改来打包负载均衡的效果. 常见的有LVS(Linux Virtual Server), 通常性能可以支持十万级并发
BIO/NIO/AIO 的区别
BIO: 同步阻塞IO, 每一个客户端连接, 服务端都会对应一个处理线程, 对于没有分配到处理线程的连接就会被阻塞或者拒绝. 相当于一个连接一个线程.

NIO: 同步非阻塞IO, 基于Reactor模型, 客户端和channel进行通行, channel可以进行读写操作, 通过多路复用器selector来轮询注册在其上的channel, 而后再进行IO操作. 这样的话, 在进行IO操作的时候再用一个线程去处理就可以了, 也就是一个请求一个线程

AIO: 异步非阻塞IO, 相比NIO更进一步, 完全由操作系统来完成请求的处理, 然后通知服务端开启线程去进行处理, 因此是一个有效请求一个线程
如何理解同步和阻塞
首先, 可以认为一个IO操作包含两个部分:
- 发起IO请求
- 实际的IO读写操作
同步和异步在于第二个, 实际的IO读写操作, 如果操作系统帮你完成了在通知你, 那就是异步, 否则就是同步.
阻塞和非阻塞在于第一个, 发起IO请求, 对于NIO来说通过channel发起IO操作请求后, 其实就返回了, 所以是非阻塞
基于Reactor模型
Reactor模型包含两个组件:
- Reactor: 负责查询, 响应IO事件, 当检测到IO事件时, 分发给Handlers处理
- Handler: 与IO事件绑定, 负责IO事件的处理
它包含几种实现方式:
单线程Reactor
这个模式, reactor和handler在一个线程中, 如果某个handler阻塞的话, 会导致其他所有的handler无法执行, 而且无法利用多核性能.

单Reactor多线程
由于decode, compute, encode的操作并非IO的操作, 多线程Reactor的思路就是充分发挥多核的特性, 同时把非IO的操作剥离开
但是单个Reactor承担了所有的事件监听, 响应工作. 如果连接过多, 还是可能存在性能问题.

多Reactor多线程
为了解决但Reactor的性能问题, 就产生了多Reactor的模式, 其中mainRractor建立连接, 多个subReactor则负责数据读写.

为什么要进行URL编码
首先, 我们区分三个概念:
- URI: uniform resource identifier, 统一资源标识符, 是一个用于标识某一互联网资源名称的字符串
- URL: uniform resource locator, 统一资源定位符, 在www上每一个信息资源都有统一的且在网上唯一的地址, 该地址就是URL
- URN: unifrom resource name, 统一资源名.
URL和URN是URI的子集, URI是更高层次的一种抽象, URI的最常见形式是URL, URN相对小一点.
http协议中参数的传递是以key=value的形式进行的, 相邻参数以&进行分割.
https://www.test.com/a/v?name=jack&age=20
服务端接受以上的字符串以&分割出每个参数, 然后以字符=分割出参数的键和值.
一般来说, URL只能使用英文字母, 阿拉伯数字和某些标点符号, 不能使用其他文字和符号. 比如, 世界上有英文字母的网址, 但是没有希腊字母的网址. 这是在网络标准RFC 1738中硬性规定的.
...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL.
只有字母和数字 [0-9a-zA-Z] , 一些特殊符号 $-_.+!*'() (不包括双引号)、以及某些保留字,才可以不经过编码直接用于URL。
这意味着, 如果URL中有汉字, 就必须编码后使用. 但是麻烦之处在于, RFC 1738并没有规定具体的编码方法, 而是交给应用程序自己决定. 这就导致URL编码成为了一个混乱的领域.
那么如何对这些不同的文字进行统一编码呢?
就是使用JS先对URL进行编码, 然后再想服务器提交, 不给浏览器插手的机会. 因为js的输出总是一致的.
JS对URL进行编码的方式有两种:
- encodeURI(): 对整个URL进行编码, 因此除了常见的符号以外, 对一些在网址中有特殊含义的符号也不进行编码. 编码后, 输出utf-8形式, 并且在每个字节前加上
%, 对应的解码函数式decodeURI() - encodeURIComponent(): 对URL的组成部分进行个别编码, 而不对整个URL进行编码. 因此,
; / ? : @ & = + $ , #这些在encodeURI中不会被编码的符号, 在encodeURIComponent中会被编码, 解码函数是decodeURIComponent
DNS 解析
在 TCP 握手之前就已经进行了 DNS 查询,这个查询是操作系统自己做的。当你在浏览器中想访问 www.google.com 时,会进行一下操作:
- 操作系统会首先在本地缓存中查询
- 没有的话会去系统配置的 DNS 服务器中查询
- 如果这时候还没的话,会直接去 DNS 根服务器查询,这一步查询会找出负责 com 这个一级域名的服务器
- 然后去该服务器查询 google 这个二级域名
- 接下来三级域名的查询其实是我们配置的,你可以给 www 这个域名配置一个 IP,然后还可以给别的三级域名配置一个 IP
以上介绍的是 DNS 迭代查询,还有种是递归查询,区别就是前者是由客户端去做请求,后者是由系统配置的 DNS 服务器做请求,得到结果后将数据返回给客户端。
PS:DNS 是基于 UDP 做的查询。
PC联网的设置详解
数据链路层数据包(以太网数据包)格式
除了应用成没有头部, 其他都有
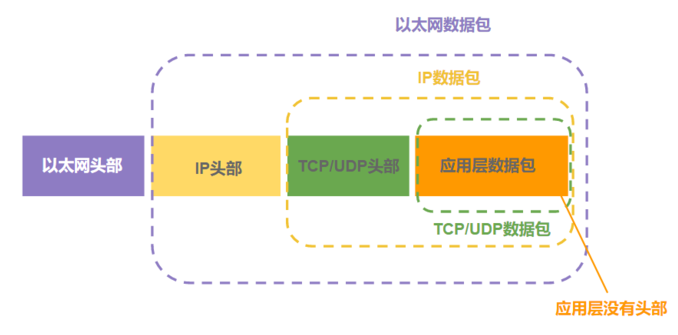
由于以太网数据包的数据部分, 最长为1500字节, 所以当一个IP包过大时, 会分割下来, 每个分隔包的头部是一样的
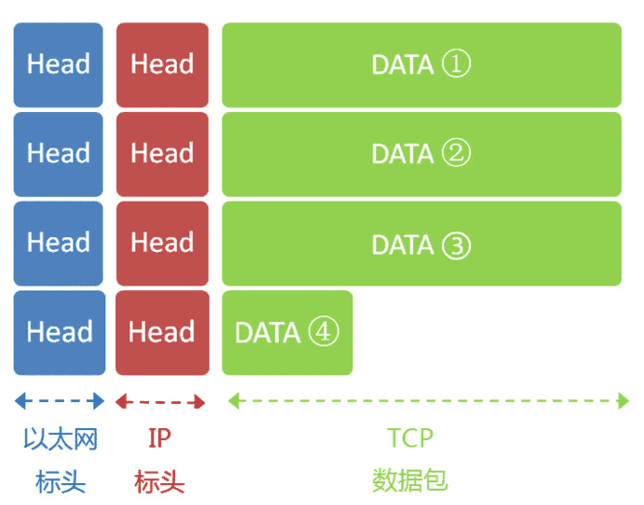
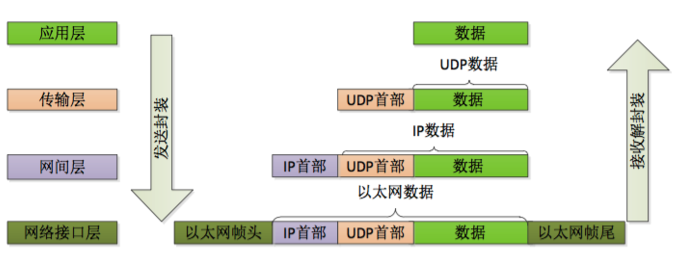
数据包在传输时的封装和解封装如下: