V8-基础
V8是由谷歌收购并使用C++开发的开源JS虚拟机引擎, 运用于Chrome浏览器以及Node环境中.
V8 底层
运行环境
V8并不是一个完整的系统, 因此需要宿主提供内容空间, 依赖由宿主提供的基础环境, 大致会包含我们熟悉的全局执行上下文, 事件循环系统, 宿主环境特殊定制的API等. 除了需要宿主提供一些基础环境之外, V8自身会使用创建好的堆栈, 并提供JS的核心功能(Object, Function, String 以及垃圾回收)
大致的流程就是: 宿主启动主进程(浏览器渲染进程, 或者Node进程) -> 宿主初始化并启动V8
执行代码
- 解释执行: 需要先将输入的源代码通过解析器编译成中间代码, 之后直接使用解释器解释执行中间代码, 然后直接输出结果
JS代码 -> 解析器转码中间代码AST -> 解释器 -> 执行
- 编译执行: 先将源代码转换为中间代码, 然后我们的编译器再将中间代码编译为机器执行
代码 -> 解析器转码中间代码AST -> 编译器 -> 二进制机器码 -> 执行
TIPS: 机器代码是以二进制文件形式存储的, 还可将机器代码保存在内存中并直接执行内存中的二进制代码
两种执行方式的区别如下:
| 类型 | 启动速度 | 执行速度 |
|---|---|---|
| 解释执行 | 快 | 慢 |
| 编译执行 | 慢 | 快 |
以前可以说JS是解释执行的, 但在V8里面不准确, 可以说它是混合执行的, 叫做JIT
- 即时编译(Just-in-time compilation): 简单的说, 就是先走解释执行, 在解释器对代码进行监控, 对重复执行评率高的代码打上tag, 成为可优化的热点代码, 之后流向编译执行的模式, 对可优化的代码进行一个编译, 转换为二进制机器码进行存储, 之后就地复用二进制, 减少解释器和机器的压力, 再执行:
代码 → 解析器转码中间代码AST → 解释器 → 执行
↓ ↑ 反编译
监控热力代码 → 编译器 → 二进制机器码 → 执行
JS是一门动态语言, 因为在程序运行的过程中可以动态增减属性, 因此不稳定, 不可复用的数据结构以及代码容易成为优化二进制代码失效的因素, 从优化编译器反编译重新回到解释器执行
字节码, 解释器, 编译器
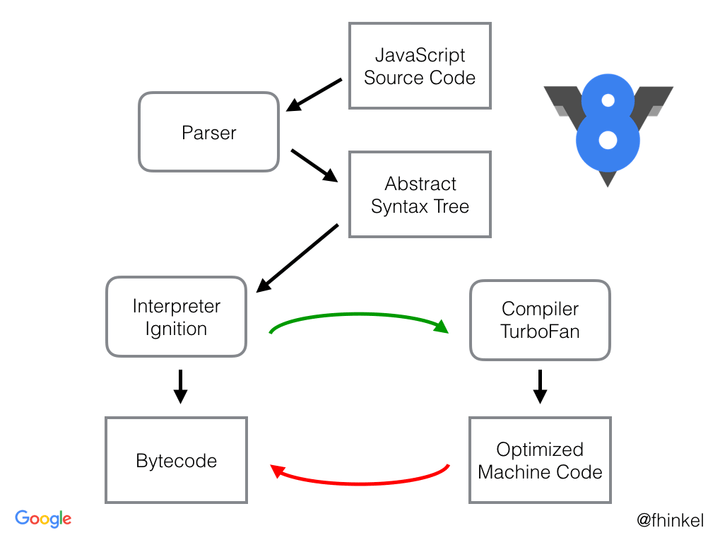
上面流程中的中间代码AST就是字节码
字节码是机器代码的抽象. 如果字节码采用和物理CPU相同的计算模型进行设计, 则字节码编译为机器代码更加容易. 这就是为什么解释器(interpreter)常常是寄存器或者堆栈. Ignition是具有累加器的寄存器.
字节码是编译过程中做了一个空间(编译执行)和时间(解释执行)上的权衡的中间代码.
我们可以将V8的字节码看做是小型的构建块, 这些构建块组合在一起构成任意的JS功能代码. V8有上百个字节码, 比如Add或者TypeOf这样的操作符, 或者想LdaNameProperty这样的属性加载符. 除此之外还有比较特殊的字节码, 比如CreateObjectLiteral.
每个字节码指定其输入和输出作为寄存器操作数. Ignition使用寄存器和累加寄存器. 几乎所有的字节码都使用累加寄存器. 它想一个常规寄存器, 除了字节码没有指定.
V8是如何处理字节码的:
- 字节码允许被解释器直接执行
- 热力代码会被优化, 从字节码编译为二进制的代码执行(字节码与二进制码的执行过程接近, 所以编译可以提效)
- 因为移动端的兴起, 所以采用了比二进制占用空间更小的字节码, 这样就可以被浏览器缓存在内存中或者被机器缓存在硬盘中
- 字节码被解释器编译的速度更快, 因此能提高启动速度, 同时直接执行的执行速度只不过比机器码慢一点
- 不同的CPU由于平台的问题需要执行不同的机器码, 字节码和机器码执行流程接近因此降低了编译器将字节码转换机器代码的时间
变量提升的原理
console.log(yyz)
var yyz = 'handsomeBoy'
// => undefined
我们都知道有JS中有变量提升的设计, 那么它是由什么原因造成的呢?
一个变量的赋值分为声明和赋值两个部分, 声明是左边, 赋值是右边.
上面的代码在编译阶段是这么处理的:
// ————————————————————————————————————————— 编译阶段
var yyz = undefined // 被提升
// ————————————————————————————————————————— 执行阶段
console.log(yyz) //打印:undefined
yyz = 'handsomeBoy'
所有表达式都是编译阶段创建变量并且赋值undefined提升到作用域中, 语句则在执行阶段触发, 此时会从作用域中查询变量
V8 中的函数
函数表达式和声明式
// 函数表达式
handsomeBoy();
var handsomeBoy = function(){
console.log(`yyz is 18 years old`);
}
// 打印:VM1959:1 Uncaught TypeError: handsomeBoy is not a function
// at <anonymous>:1:1
函数表达式也是声明表达式, 也会被想变量一样进行提升, 然后赋值为undefined, 所以执行阶段handsomeBoy()这个方法会报错.
函数声明式则如下:
// 函数声明式
handsomeBoy();
function handsomeBoy(){
console.log(`yyz is 18 years old`);
}
// 打印:`yyz is 18 years old`
其编译阶段的代码看起来如下:
// 编译阶段代码
function handsomeBoy(){
console.log(`yyz is 18 years old`);
}
handsomeBoy();
其原因在于: V8 在变量提升的阶段(编译阶段), 如果遇到函数声明, 那么会在内存中创建该函数对象, 并提升整个函数对象, 而不是赋值为undefined, 这是它不同于变量提升的地方.
惰性解析和闭包
V8对函数进行了名为'惰性解析'的优化, 起因是因为: 当函数代码内容比较多的时候, 解析和编译的时间都比较长, 缓存内存的占用量比较大.
比如:
function handsomeBoy(name, age) {
console.log(`${name} is ${age} years old`)
}
handsomeBoy('yyz', 18)
V8在解析阶段会把函数对象分为两块内容: name以及code
// handsomeBoy Function Object
{
name: handsomeBoy,
code: `console.log(${name} is ${age} years old)`,
}
解析器在解析中如果遇到了函数式声明, 会忽略内部代码Code, 直接解析并编译顶层函数字节码. 而在执行函数的时候回通过handsomeBoy函数对象, 解析编译内部的code内容.
当然也有特殊的情况:
- 闭包(函数内部嵌套函数, 同时允许查找函数外部变量作用域)
- 函数语法错误(错误的函数语法没必要再进行惰性解析)
闭包: 通常函数的作用域及其左右变量都会在函数执行结束后被销毁; 而闭包, 可以访问上级作用域, 即便外层函数执行完毕, 外层函数的作用域中能被闭包访问, 会一直保存在内存中, 直到闭包不存在
为了解决这两个特殊情况, 预解析器就登场了, 主要作用是为了解决上面的两种特殊情况, 会先对code中的代码进行一个粗略的预解析:
- 遇到语法错误的时候直接抛出
- 遇到闭包会把外部变量从栈复制到堆中, 下次直接使用堆中的引用(以防止执行先后顺序导致闭包引用的变量已经出栈被回收)
V8的栈溢出
function fac(n) {
if (n === 1) return 1
return n * fac(n - 1)
}
fac(5) // 120
栈是内存中连续的一块存储空间, 主要负责函数的调用, 并采用FILO(先进后出)的结构
V8对栈空间进行了大小限制, 所以当栈中数据过多会产生溢出错误:
VM68:1 Uncaught RangeError: Maximum call stack size exceeded
如果使用不当, 比如不规范的代码触发频繁的垃圾回收, 或者某个函数执行时间过久, 这些都会占用宿主环境的主线程, 从而影响到程序执行效率, 甚至导致宿主环境的崩溃.
为了解决栈溢出的问题, 我们可以使用异步队列中的宏微任务, 例如setTimeout将要执行的函数放到其他的任务中去执行, 也可以使用Promise来改变栈的调用方式, 主要还是因为异步队列与同步调用栈的执行顺序有所不同. 当然如果采用了微任务递归调用会导致页面不报错, 但是会产生卡死, 因为需要将微任务队列中的任务清空, 这回导致页面上的IO, 用户操作阻塞.
最可靠的访问是尾递归优化, 用来删除调用栈外层无用的调用帧, 只保留内存函数的调用帧, 来节省浏览器的内存. 即在递归的最后返回一个纯函数, 以上面的代码为例, 可以这样改造:
function fac(n, total) {
if (n === 1) return total
return fac(n - 1, n * total)
}
fac(5, 1) // 120
TIPS:
- 如果使用外层函数的变量, 可以通过参数的形式传入到内层的函数中
- 尾调用优化只会在严格模式下启用, 非严格模式无效
- 如果环境不支持尾递归优化, 不影响代码的正常运行
V8 对象属性访问
function yyz() {
this['A'] = 'A'
this[0] = '2'
this['1'] = 3
this[2] = '4'
this['handsome'] = 5
this[7.7] = 7.7
this[888] = '6'
this['B'] = 'B'
}
const handsomeBoy = new yyz()
for (let key in handsomeBoy) {
console.log(`${key}:${handsomeBoy[key]}`)
}
在不同的浏览器中, 对象属性的访问顺序是不同的, 以chrome中的v8为例:
0:2
1:3
2:4
888:6
A:A
-1:1
handsome:5
7.7:7.7
B:8
在V8的对象中有分两种属性, 排序属性(elements)以及常规属性(properties), 数字被分类为排序属性, 字符串则是常规属性. 其中排序属性按照数字大小升序, 而常规属性按照创建顺序升序, 总体的顺序为先进行排序属性, 在进行常规属性.
对象内属性
function demo() {}
var demo1 = new demo()
var demo2 = new demo()
var demo3 = new demo()
for (var i = 0; i < 10; i++) {
demo1[new Array(i + 2).join('a')] = 'aaa'
}
for (var i = 0; i < 12; i++) {
demo2[new Array(i + 2).join('b')] = 'bbb'
}
for (var i = 0; i < 30; i++) {
demo3[new Array(i + 2).join('c')] = 'ccc'
}
如果一个对象中保存了很多属性, 那么每次都需要从demo -> properties -> a, 为了优化这个过程, v8设计了对象内属性.
当对象的属性小于10个的时候, 对象不会生成properties属性, 而是直接保存在对象内的, 为了减少查找这些属性查找流程, 在对象内直接生成映射
当对象的属性大于10个的时候, 会以快属性的方式, 在properties下创建顺序存放在(0, 1). 相较于对象的内属性, 快属性需要额外多一次的properties的寻址事件, 之后便是与对象内属性一致的线性查找.(properties的属性是有规律的类似数组, 链表存放)
当对象的属性大于20个的时候, 在properties里的属性已经不线性了, 此时已经使用了兰列表(哈希-分离链路)来存储
V8采用了两种结构来处理数据量大小的问题:
| 结构 | 数据类型 | 执行速度 |
|---|---|---|
| 线性结构 | 数组、链表 | 快 |
| 非线性解构 | 哈希 Map(分离链路) | 慢 |
总的来说:
- 排序顺序数字按大小排序, 字符串按照先后执行顺序排序
- 数字存储在排序属性, 字符串存储在常规属性. 当属性在10个以内会直接在内部生成属性, 大于10个的时候会在
properties中线性存储, 数据量大于20个的时候, 会变为散列表存储
隐藏类
ts中可以使用interface来定义数据结构和包含的属性:
interface Post {
name : string
content: string
}
在java, c++这样的静态语言中, 类型一旦创建便不可更改, 属性可以通过固定的偏移量进行访问, 而v8为了优化属性的查找创建了隐藏类, 可以提升存储的速度以及节省空间.
const post = {
name: 'yyz',
content: 'handsome',
}
我们在创建对象的时候隐藏类会存储属性在内存空间的偏移量, 如上图的offset, 访问post.name会直接通过隐藏类的偏移量查找属性.
复用对象的attribute, 每次新增, 删除一个属性就会创建新的隐藏类.
当读取到post.content属性的时候回创建新的隐藏类, 其中包含了name, content两个属性, 而其中的name属性执政指向之前创建好的post.name的隐藏类引用, 用偏移减少了重新创建的开销.
以这段代码为例:
const post = {}
post.name = 'yyz'
post.content = 'handsome'
这段代码先创建空对象再赋值, 然后与上文直接创建含属性的对象. 虽然结果是相同的, 但是隐藏类的地址是不一样的. 是因为第一步是单独创建空对象这一步.
因此在同一个隐藏类的两次成功的调用之后, V8省略了隐藏类的查找, 并简单地将该属性的偏移量添加到对象指针本身. 对于该方法的所有下一次条用, V8引擎都假定隐藏类没有更改, 并使用之前的查找存储的偏移量直接跳转到特定属性的内存地址.
内联缓存
gzip和http2压缩的本质就是利用重复的内容去拼装不重复的内容. V8对于对象读写也进行了缓存.
比如post.name这个语句如果在一个循环中执行(一定规律下执行多次), V8就会继续进行优化, 针对这个动作语句存储偏移量, 缩短对象属性的查找路径, 从而提升执行效率.
删除属性
delete post.name
删除对象中的属性容易导致稀疏索引退化为哈希存储. 会造成负优化, 从快属性变为了慢属性.
优化对象写方式
- 保证相同顺序相同属性赋值:
const post1 = {
name: 'yyz',
content: 'handsome',
}
const post2 = {
content: 'handsome',
name: 'yyz',
}
- 避免空对象, 尽量一次性初始化属性
- 减少 delete